Headless Quickstart
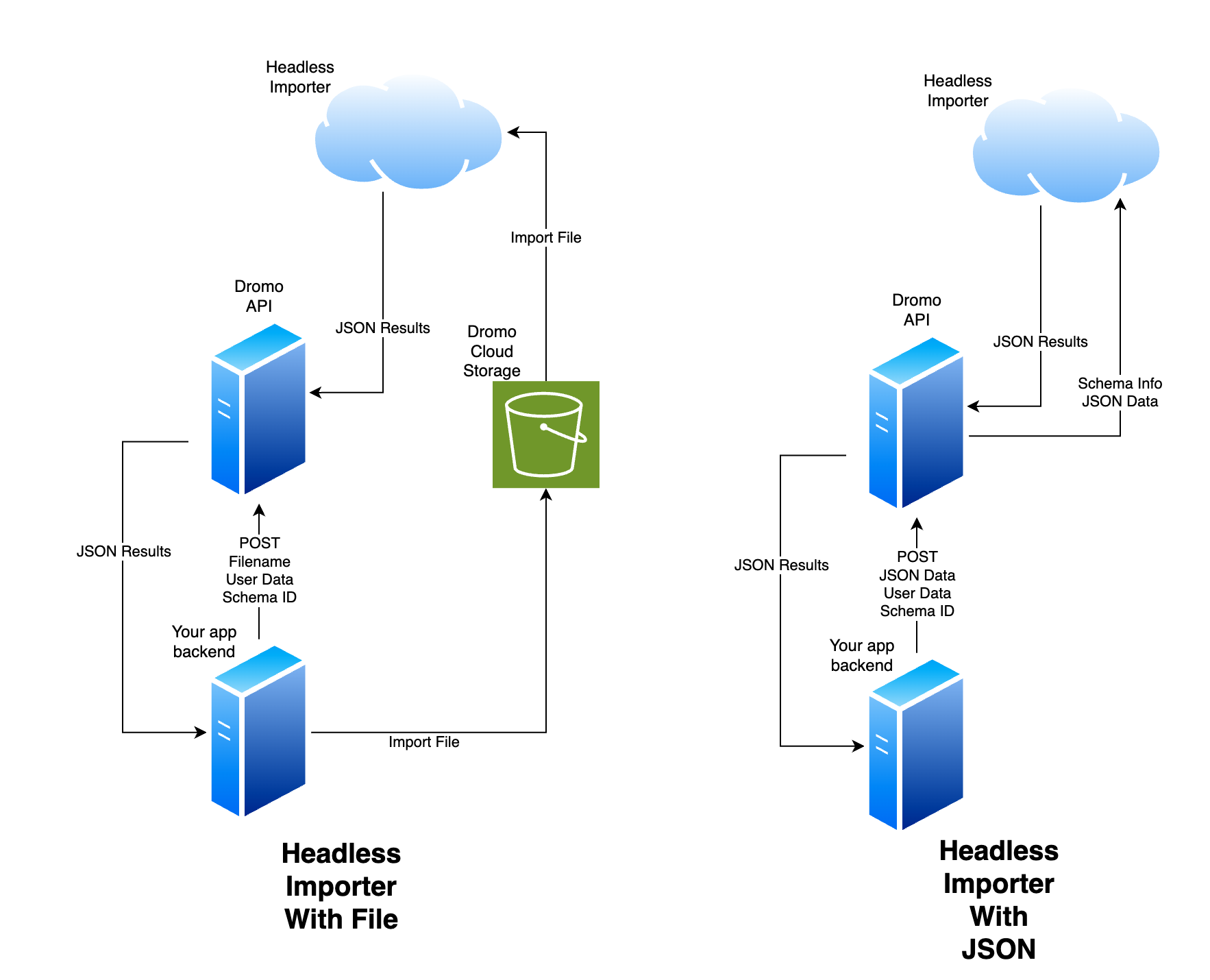
The Headless API allows you to import CSVs and spreadsheet files programatically.
With Headless, you can send a file or JSON payload to Dromo and specify a schema that defines the desired shape and constraints of the final data file.
If there are no problems with the import, Dromo will send you the cleaned data in the JSON format, just like an embedded import.
If there are any issues with the import (like missing columns or failing data validations), Dromo provides a URL for a user to resolve them using the same interface as for embedded imports.
Activation
To get started with the Headless API, Dromo will need to enable Headless for your organization. The Headless API is a premium add-on to Dromo Enterprise.
Once your account is set up, get in touch and we can get you ready to go!
Rate Limits
The Headless API has the following rate limits:
- Creating headless imports: 20 requests per minute
- Polling import status: 12 requests per minute per import
These limits help ensure service stability. For high-volume use cases, we recommend using webhooks instead of polling to avoid hitting rate limits.
Using the Headless Importer
A headless import can be run either on a file or a JSON object. The steps below walk through the procedure for either type of import.
You will need a saved schema to guide the import. For more information about saved schemas, check out the Schema Studio Guide or the Saved Schema API.
- Importing a File
- Importing JSON
1. Create a new headless import
The import process starts by creating a new headless import record. You will use this record to check the status of the import and retrieve the results.
To create a headless import, use the create headless import endpoint.
You must provide two things when creating the import:
- The ID of the saved schema you want to use
- The original filename of the file you want to import
Here is an example request:
curl \
-H "Content-Type: application/json" \
-H "X-Dromo-License-Key: your-backend-key" \
-X POST \
'https://app.dromo.io/api/v1/headless/imports/' \
-d '{
"schema_id": "4eefe3fe-7181-4562-aa28-8cfe1c5bdf1b",
"original_filename": "data.csv"
}'
Each headless import allows you to import only one file.
2. Upload the file
Once you've created the import record, Dromo will return an ID
and a URL (in the "upload" field) where you can upload the file.
Store the ID for later use (you need it to fetch the import status and results).
To upload the file, make a PUT request to the URL, with the file as the body. Note that the upload URL is only valid for 30 minutes, so only create the import record when you are ready to upload the file.
Here is an example request for uploading the file:
curl \
-X PUT \
'https://dromo-headless-imports-prod.s3.us-west-2.amazonaws.com/74033520-fee6-4edb-9a30-8c5b3fcd513f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIARY5HJCMTO2AUIBEU%2F20230227%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Date=20230227T181454Z&X-Amz-Expires=1800&X-Amz-SignedHeaders=host&X-Amz-Signature=14241560a7d9dff1e9d2bb8d8d1445880df1860a9c96728c5fb0dd2e123c0011' \
--data-binary "@/path/to/data.csv"
3. Wait for the import to run
Dromo will automatically begin the import process once the upload is complete.
1. Create a new headless import
The import process starts by creating a new headless import record. You will use this record to check the status of the import and retrieve the results.
To create a headless import, use the create headless import endpoint.
You must provide two things when creating the import:
- The ID of the saved schema you want to use
- The complete JSON data
Here is an example request:
curl \
-H "Content-Type: application/json" \
-H "X-Dromo-License-Key: your-backend-key" \
-X POST \
'https://app.dromo.io/api/v1/headless/imports/' \
-d '{
"schema_id": "4eefe3fe-7181-4562-aa28-8cfe1c5bdf1b",
"initial_data": '[{"product": "widget1", "transaction": "foo123"}, {"product": "widget2", "transaction": "foo456"}]'
}'
2. Wait for the import to run
The import will start immediately.
Handling Import Results
You can query for the current import status using the retrieve headless import endpoint.
The import status will be one of the following:
AWAITING_UPLOAD: The import record has been created, but the import file has not yet been uploaded.PENDING: The import file has been received, and the import process will begin shortly.RUNNING: The import process is currently running.SUCCESSFUL: The import was successful and the result data is ready to be retrieved.NEEDS_REVIEW: The import could not be completed due to data validation errors, and requires human attention.FAILED: The import encountered a fatal error, and cannot be processed.
Successful import
If the import data did not have any issues, the import will be in the SUCCESSFUL state.
You can be notified when an import completes in two ways:
Dashboard-configured webhooks (RECOMMENDED):
The recommended approach is to configure webhooks in the Dromo dashboard under the Webhooks section. This method provides several advantages:
- More reliable delivery with retry mechanisms
- Detailed event information
- Easier configuration and management
- Better security
For detailed information on setting up and using dashboard webhooks, see the Webhooks documentation.
These webhooks will receive detailed information about the completed import:
{
"event": "import_completed",
"data": {
"id": "911224fa-c609-46d2-a278-bc2250d2be91",
"filename": "contacts (8).csv",
"user": null,
"created_date": "2025-02-25T17:07:03.769925Z",
"import_type": "HEADLESS",
"status": "SUCCESSFUL",
"num_data_rows": 92,
"development_mode": false,
"has_data": true
}
}
After receiving this webhook notification, use the import ID from the payload to retrieve the presigned URL for downloading the data:
curl \
-H "X-Dromo-License-Key: your-backend-key" \
-X GET \
'https://app.dromo.io/api/v1/headless/imports/{id}/url/'
The response will contain a presigned URL that you can use to download the data:
{
"presigned_url": "https://dromo-user-imports.s3.us-west-2.amazonaws.com/b3f0ff47-07e0-4c98-90de-5451aff066c8.json?X-Amz-Algorithm=...&X-Amz-Credential=...&X-Amz-Date=...&X-Amz-Expires=1800&X-Amz-SignedHeaders=host&X-Amz-Signature=..."
}
Legacy webhookUrl (DEPRECATED):
If you define a legacy webhookUrl in your schema, it will still fire when the import completes successfully, but this method is deprecated and may be removed in the future.
Alternative: Polling for completion
If you prefer not to use webhooks, you can poll the retrieve headless import endpoint to check the status:
curl \
-H "X-Dromo-License-Key: your-backend-key" \
-X GET \
'https://app.dromo.io/api/v1/headless/imports/{id}/'
Once the status shows SUCCESSFUL, you can then retrieve the presigned URL using the headless import URL endpoint:
curl \
-H "X-Dromo-License-Key: your-backend-key" \
-X GET \
'https://app.dromo.io/api/v1/headless/imports/{id}/url/'
Remember that polling is subject to rate limits (12 requests per minute per import). For production systems with many imports, webhooks are strongly recommended to avoid hitting these limits.
Import needs review
If the import has issues that need manual review, the import will be in the NEEDS_REVIEW state.
This can happen for several reasons:
- The header row could not be determined
- The columns could not be mapped automatically
- There are failing data validations, and invalidDataBehavior is set to
BLOCK_SUBMIT
When an import is in the NEEDS_REVIEW state, the data returned by the retrieve headless import endpoint will include a "review_url" field.
This is a URL which you can navigate to in a browser to resolve the import issues using Dromo's
import UI.
After resolving the issues and completing the import, the import will transition to the SUCCESSFUL state.
Import failed
An import will enter the FAILED state if it has an unrecoverable error.
Some examples of unrecoverable errors are:
- The import file was corrupted and could not be parsed
- The import file was completely empty
- A custom hook threw an unhandled exception
Failed imports do not have results and also do not have a review URL.